| КОМПЬЮТЕРЫ |
  |
Описание FPGA-суперкомпьютера Maxwell
Общие сведения
Maxwell является
высокопроизводительным реконфигурируемым компьютером,
разработанным альянсом FHPCA для демонстрации
возможностей создания вычислительных приложений на базе ПЛИС-технологий.
Схема суперкомпьютера
Техническое описание
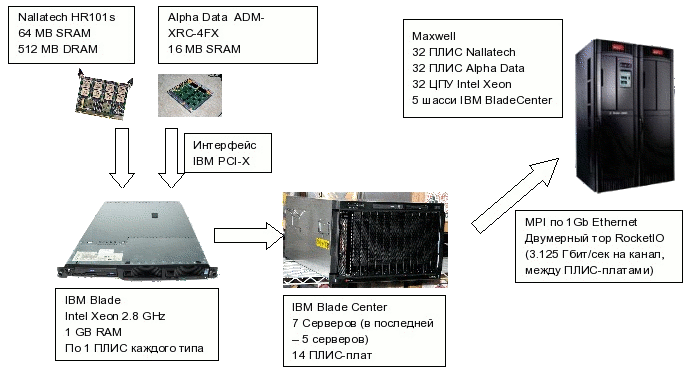
Физически Maxwell состоит из 32 блейд-серверов, управляемых при помощи
IBM Blade Center. Каждый сервер содержит один обычный процессор Intel Xeon с
тактовой частотой 2.8 ГГц с 1 ГБ ОЗУ, а также 2 ПЛИС-платы различных типов.
Один тип ПЛИС-платы разрабатывается фирмой Alpha Data, а другой - фирмой
Nallatech (обе входят в состав FHPCA). Платы сделаны на основе ПЛИС Xilinx Virtex-4
и соединяются с основным процессором при помощи интерфейса IBM PCI-X
(не путать с PCI Express!). Платы Alpha Data ADM-XRC-4FX содержат 16 МБ
статической памяти и 1ГБ динамической памяти (на плату), в то время как платы
Nallatech H101 содержат соответственно 64 МБ и 512 МБ.
Узлы суперкомпьютера Maxwell объединены двумя типами вычислительных сетей.
С одной стороны, это стандартная сеть Gigabit Ethernet, которая соединяет обычные
процессоры и по которой, в частности, в этом кластере работает MPI. С другой стороны,
это соединяющая ПЛИС-платы сеть RocketIO. Она соединяет все платы в системе по
топологии двумерного тора со скоростью 3.125 Гбит/канал.
Требования к программам
Для эффективного исполнения на ПЛИС-системах вообще (и Maxwell в частности)
программа должна удовлетворять ряду требований, а именно:
- Значительное время программа выполняет вычислительные ядра. В этом случае
использование ПЛИС можно рассматривать как оптимизацию, которая заменяет эти ядра
эффективной реализацией на ПЛИС.
- Малый размер вычислительных ядер обусловлен небольшим количеством вычислительных
ресурсов ПЛИС систем, и как следствие - накладываемыми ограничениями на сложность
реализуемых ядер.
- Ядра должны работать с собственными, а не разделяемыми данными (особенность
систем, где ПЛИС стоят на отдельной плате). ПЛИС-платы имеют свои банки памяти,
обмен с которыми идет на значительно большей скорости, чем с ОЗУ ЦПУ. Поэтому для
максимальной эффективности все данные должны помещаться в эту память.
- Передача данных между ПЛИС-платой и ОЗУ ЦПУ должна быть минимальной по сравнению
с объемом вычислений (особенность систем, где ПЛИС стоят на отдельной плате).
Другими словами, задача должна обладать высокой вычислительной мощностью, чтобы
эффективно обрабатываться на ПЛИС.
- Ограниченное пространство для работы самих ядер вытекает из сравнительно
небольшого (0.5 - 1 ГБ) объема ОЗУ ПЛИС и из невысокой скорости обмена ПЛИС - ЦПУ.
Другими словами, ядро не должно порождать больших вспомогательных массивов данных
(т.е. больших по порядку, нежели размер входных или выходных данных).
- Параллельная декомпозиция задачи для ПЛИС должна хорошо ложиться на топологию
двумерного тора (требование Maxwell - так как отдельные ПЛИС-платы объединены именно
по этой топологии.
Методология
Один из возможных методов создания программ для ПЛИС-систем можно представить
следующим образом:
- Создание программы для центрального процессора для решения задачи. Можно
использовать любые известные языки программирования - C, FORTRAN и т.д.
- Выделение вычислительно интенсивных участков программы (ядер). Это можно
выполнять как при помощи профилировщика, так и привлекая соображения о структуре
задачи и т.д.
- Рефакторинг исходной программы. Сюда входит прежде всего вынесение ядер в
отдельные функции или процедуры. Кроме этого, ядра должны быть реорганизованы
таким образом, чтобы они не использовали разделяемые массивы данных с другими
частями приложения, поскольку на ПЛИС это будет невозможно. Разработчики Maxwell
в данном случае предлагают также абстракцию "ускоряемой части задачи" при помощи
ООП. Подробнее смотрите в
Parallel Toolkit.
- Использование библиотек компонент для ПЛИС для решения задачи. Стандартные
ядра (например, преобразование Фурье, умножение матриц и т.д.) заменяются на их
готовые реализации для ПЛИС (если такие есть). С одной стороны, трудозатраты на это
малы по сравнению с написанием кода для ПЛИС. С другой стороны, если имеется хорошая
библиотека компонент (а она только начинает создаваться), это может обеспечить
достаточный рост производительности программы при небольших трудозатратах. Примером
подобного инструмента может служить
Parallel Toolkit.
- Написание ядер для конкретных задач и ПЛИС. Это наиболее трудоемкий этап всего
процесса программирования ПЛИС. Он позволяет получить максимальное ускорение задачи,
однако трудозатраты при этом также значительно увеличиваются. Для программирования
ПЛИС можно использовать специальные языки описания аппаратуры (Verilog, VHDL),
диалекты C, приспособленные для работы с аппаратурой, или языки более высокого уровня,
которые транслируются в программы для ПЛИС.
Примеры программ
На Maxwell решались три типа задач. Во-первых, это задача оценки цены опционов
при помощи метода Монте-Карло ("Опционы Монте-Карло"). Во-вторых, это задача
построения трехмерных изображений по набору стереоснимков или стереовидео
("Построение изображений"). Наконец, третья задача ("Поиск нефти и газа") - это
решение на ПЛИС обратной задачи поиска месторождений нефти и газа на основе
электромагнитного зондирования. Для каждой задачи приведены затраты на разработку
(большую часть его составляет именно написание прошивок для ПЛИС). Для каждой задачи
также сравниваются времена ее счета: обычный кластер из N процессоров против системы
из N ПЛИС-ов (ЦП в этом случае не используется для расчетов).
Результаты по всем задачам приведены в следующей таблице.
| Задача
| Время разработки
| Ускорение
|
| Опционы Монте-Карло
| несколько человеко-недель
| х109 - х322 (разные для разных типов ПЛИС)
|
| Построение изображений (Image-Based Rendering)
| 6 человеко-месяцев
| х2.52 (один узел, включая пересылку данных, без - х3.6), х2 (8 узлов)
|
| Поиск нефти и газа
| 12 человеко-месяцев
| х4.83 (8 узлов)
|
© Лаборатория Параллельных
информационных технологий НИВЦ МГУ
