Проблемы, связанные с рекурсивными алгоритмами при их записи на языке COLAMO
Постановка задачи и суть проблемы
Алгоритмы с рекуррентными соотношениями представляют собой довольно
трудную проблему при любом распараллеливании, не только на ПЛИСах.
Напомним, что под такими алгоритмами обычно понимают вычисление
некоторой последовательности результатов, каждый из которых зависит от
предыдущего (или нескольких предыдущих). Говоря иначе, в алгоритме
должны присутствовать вычисления вида xi = f (xi-1,...).
Тогда в этом куске вычислительной задачи у нас получается чисто
последовательное выполнение, и не вполне понятно, как нам использовать
параллельные вычислительные ресурсы (ПЛИС ли это или другая
вычислительная система), чтобы ускорить эту часть алгоритма. Хорошо,
если у нас есть большой параллельно выполнимый набор таких рекурсий -
тогда их просто надо реализовать параллельно, и проблемы, как
распараллелить саму рекурсию, у нас не возникает. Но если такого набора
нет - что делать?
Примеры рекурсий в алгоритмах
Классический пример рекурсии в алгоритме - схема Горнера для вычисления
частного от деления многочлена n-й степени одной переменной Pn(x)
= a0xn + a1xn-1 + ... + an-1x
+ an на двучлен x - c, с получением многочлена n-1-й степени
Qn-1(x) = b0xn-1
+ b1xn-2 + ... + bn-2x + bn-1 и остатка от
деления bn (равного Pn(с)). При этом у нас искомые
коэффициенты и остаток вычисляются по рекуррентной формуле: bi
= c bi-1 + ai.
Есть и более простые алгоритмы, выполненные в рекуррентном виде.
Скажем, при нахождении суммы всех элементов массива сумма n элементов
представляется как сумма n-го элемента и вычисленной ранее суммы n-1
элементов, при нахождении максимума из всех элементов массива максимум
n элементов представляется как максимум n-го элемента и вычисленного
ранее максимума n-1 элементов.
Ассоциативные операции и запись разных реализаций на COLAMO
Рассмотренные выше примеры отличаются тем, что, как максимум, так и
математическая сумма
ассоциативны, и на этой ассоциативности можно сыграть при реализации.
Если мы "тупо" запишем то же суммирование в неизменном виде на COLAMO
for i = 1 to n do;
s = s + x[i];
end;
то в получившейся схеме
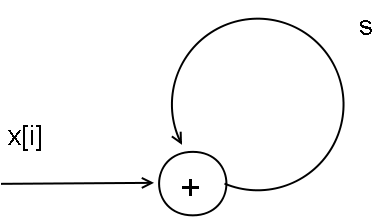
казалось бы, будет возможность подать на сумматор поток данных
такт за тактом? Оказывается, нет - сумматор действительных
нормализованных 32-битных чисел в библиотеке элементарных
операций реализован вовсе не за 1 такт, а за 18. Поэтому при такой
реализации подавать на него новый элемент массива мы сможем только
каждые 18 тактов. Поэтому 17 из 18 ступеней конвейера, который
представляет из себя этот сумматор, будут простаивать.
Аналогичная, хоть и не такая острая, проблема будет и при нахождении
максимума аналогичным способом. Реально для этого нахождения надо в
цикле выполнить две операции - сравнения двух чисел и выбора из них
мультиплексором по результату сравнения:
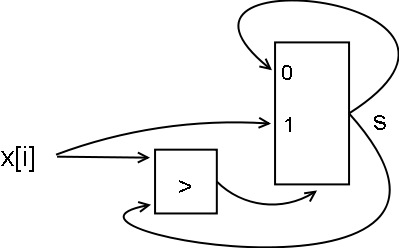
Здесь остроту снижает то, что, хотя операций и две, но даже вместе они
выполняются существенно быстрее, чем сложение (по описанию библиотеки -
по 1 такту, поэтому в сумме 2 такта). Но всё равно мы видим, что
потактовой подачи потока элементов массива нам так не получить.
Если мы теперь хотим всё же дать потоку данных из массива идти
потактово, то получается, что нам необходимо воспользоваться
ассоциативностью операций. В случае с сумматором нам придётся
использовать регистровый массив для хранения частичных сумм (элементов
через 18), а потом записать отдельно, как их просуммировать (что само
по себе займёт отдельный ресурс - воистину, "хвост вытащили - нос
увяз"). Само по себе это программирование так нетривиально, что такую
программу суммирования мы пока не приводим.
В случае же вычисления максимума тактов всего 2, и разбиение нужно
всего на два потока, что можно записать через следующую программу.
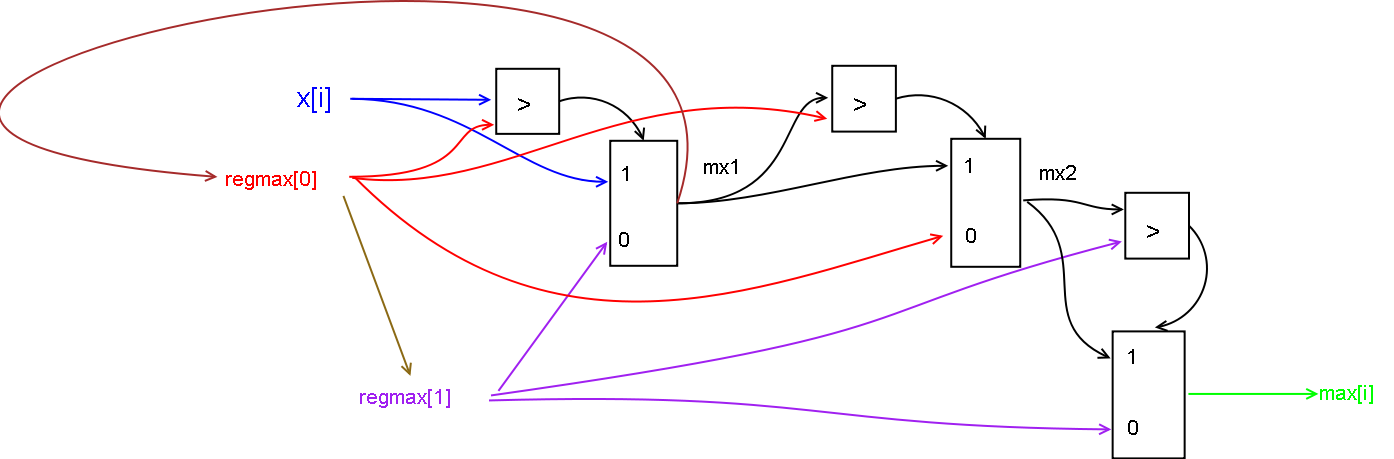
Program Maximum_v6;
Include MyLibNewElementV_5;
var x : array real [100:stream] mem;
var max : array real [100:stream] mem;
var regmax : array real [2:vector] reg;
var i : number;
var mx1,mx2 : real com;
Cadr Cadr1;
for i:=0 to 100 do
begin
if x[i]>regmax[0] then
begin
mx1:=x[i];
end;
else
mx1:=regmax[1];
regmax[0]:=mx1;
regmax[1]:=regmax[0];
if mx1>regmax[0] then
mx2:=mx1;
else
mx2:=regmax[0];
if mx2>regmax[1] then
max[i]:=mx2;
else
max[i]:=regmax[1];
end;
EndCadr;
End_Program.
Здесь вместо одной переменной s на выходе
используется массив max, в
котором после исполнения цикла можно увидеть, как менялся "максимум" в
процессе счёта, а в цикле - регистровый массив из 2 элементов, через
который и организуются задержки на 2 такта.
Вернёмся к сути подобного приёма "разделения потоков. Она - в
подстановке формулы рекурсии xi =
f (xi-1,...) в саму себя. Если у нас свойства
ассоциативности и дистрибутивности операций позволяют упростить саму
формулу в другую , например, в xi
= f (xi-k,...), где k - это величина, достигающая
длины конвейера, то мы можем достичь реальных ускорений. Например,
в случае схемы Горнера есть возможность воспользоваться ассоциативностью
операции матричного умножения, и, перейдя на матричную форму записи
схемы, распараллелить её.
Неупрощаемые формулы - нераспараллеливаемый случай
В случае же невозможности упрощения формул после
подстановки подобный подход неприемлем по простой причине. Если без
выполнения подстановки у нас будет схема
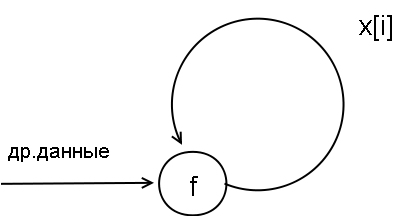
с задержкой k тактов на функции f, то после подстановки мы
получим схему работы
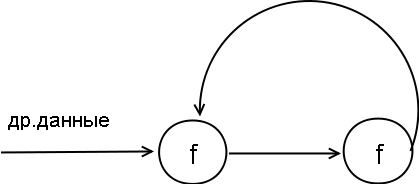
с двумя устройствами для функции f и вдвое большей задержкой 2k и, соответственно,
с той же долей загруженности устройств. Так что никакого
выигрыша без упрощения формул нам не получить.
Неполная загрузка оборудования
Строго говоря, даже в приведённом выше вычислении максимума
у нас всё имеющееся оборудование загружено постольку, поскольку мы
считаем полезными все промежуточные результаты. Будь иначе, 2/3
имеющегося оборудования (по 2 сравнителя и мультиплексора) простаивали
бы, срабатывая лишь после того, как вычислялись бы максимумы чётных и
нечётных элементов массива. Так что сама по себе ассоциативность
операций тоже не гарантирует нам хорошую производительность и
загруженность оборудования. Однако заметим, что в данном случае
такой большой простой связан с малой глубиной конвейера, работающего в
основном цикле (1+1=2). В случае суммирования она достигает 18, что
позволяет нам с помощью небольшого массива регистров разбить поток на
вычисление 18 частичных сумм, с последующим их
суммированием
(хотя бы и обычным медленным способом - по суммированию на 18 тактов - это будет
всего 18х17=306 тактов, что вполне терпимо по сравнению с временем
вычисления частичных сумм, если размерность массива очень велика.
Высказанные выше соображения показывают, как важно знать при
программировании на COLAMO, сколько тактов уходит на элементарные
математические операции.
Осторожность при упрощении формул
Выше, разбирая суммирование, Горнера, максимум, мы использовали ассоциативность и дистрибутивность
математических операций сложения и умножения. Однако реально, при
вычислениях на компьютерах, ассоциативными являются только
минимаксные операции. Использование ассоциативности умножения и
сложения меняет сам алгоритм и, как следствие, устойчивость. Поэтому
даже в "хорошем" случае рекурсии с упрощаемыми после подстановки
формулами необходимо исследование получившегося нового алгоритма на
устойчивость.
Данная страница написана по
материалам рабочего семинара НИИ МВС ЮФУ по языку COLAMO.